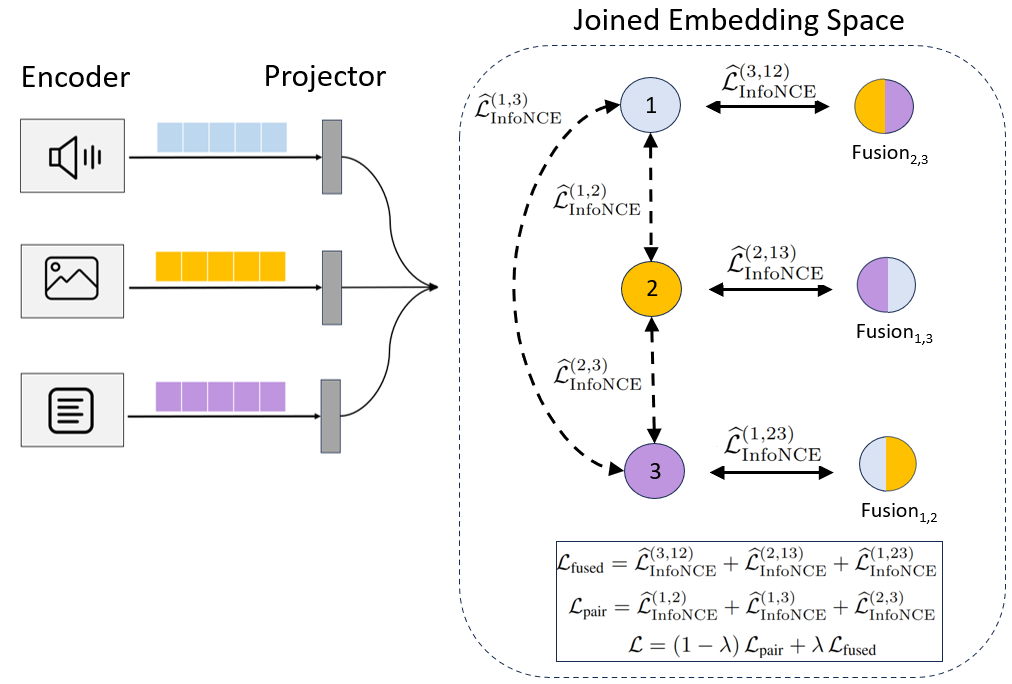
1. Pairwise contrastive alignment
Each modality is encoded and projected into a shared space. Conventional contrastive terms preserve direct correspondence
across ordered modality pairs.
2. Fusion branch for higher-order structure
A lightweight fusion module combines two modalities into a joint embedding and aligns that fused representation with the held-out modality.
This directly supervises interactions that cannot be recovered from pairwise terms alone.
3. Unified training objective
The final objective combines pairwise and fused higher-order terms. The resulting representation space remains usable for standard unimodal retrieval,
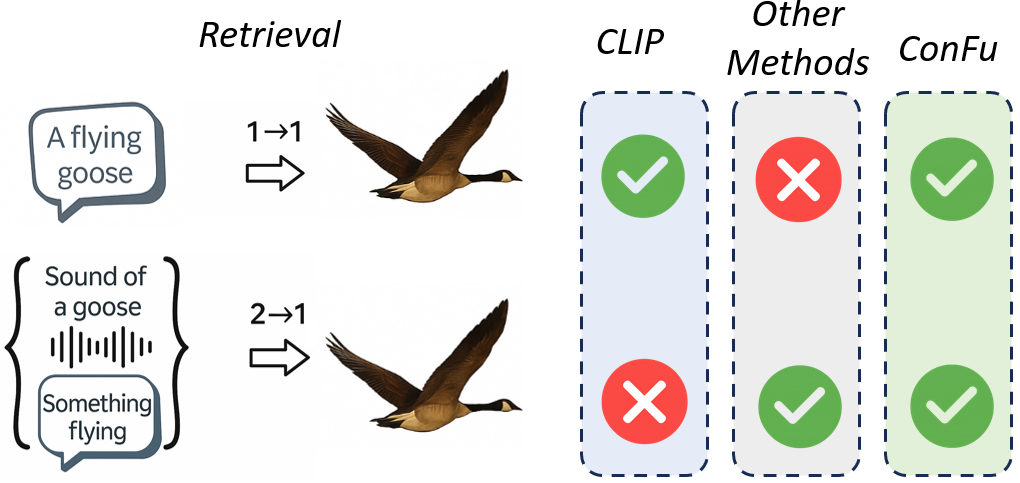
while also supporting fused two-to-one retrieval and classification.
- Jointly embeds individual modalities and fused modality pairs
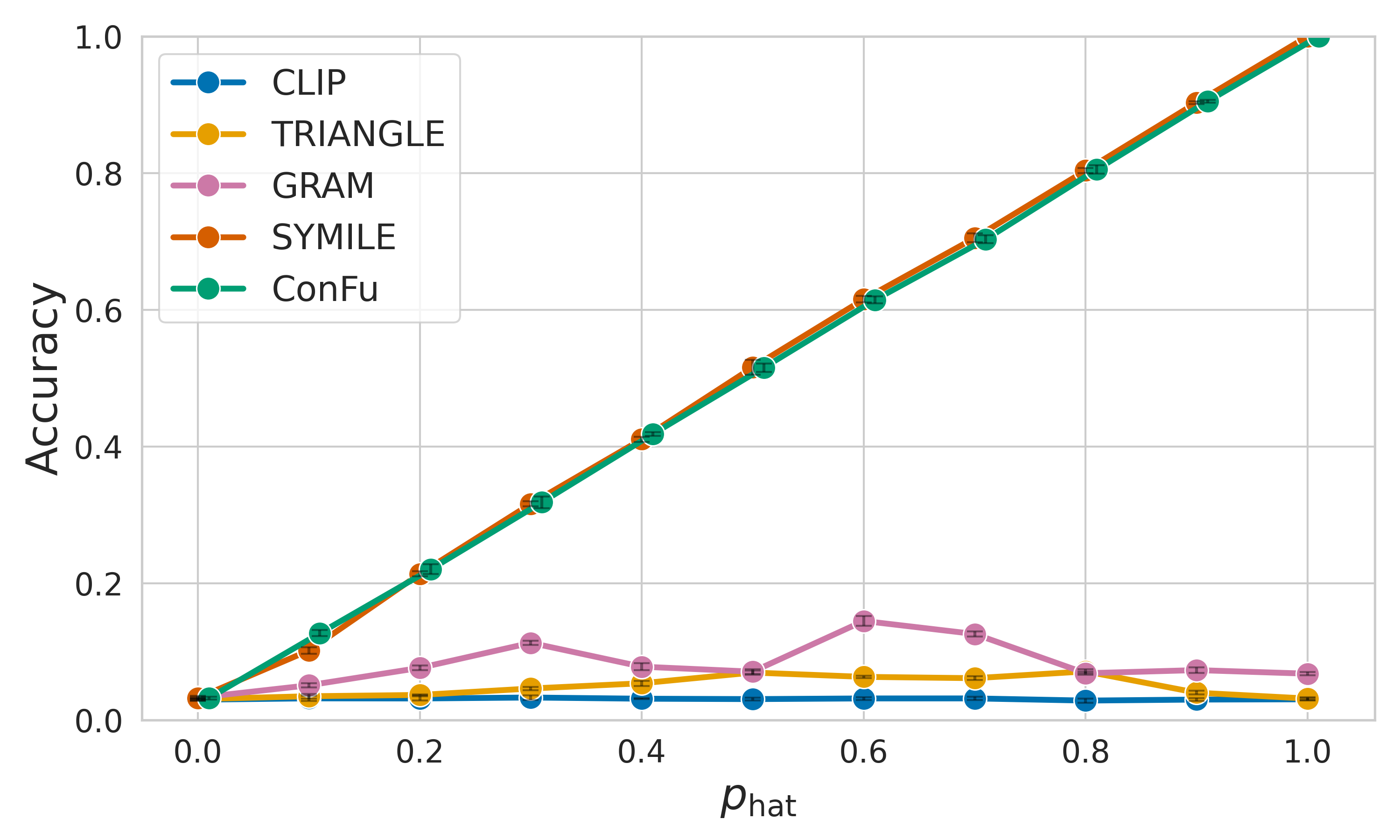
- Captures XOR-like dependencies missed by purely pairwise objectives
- Supports both 1-to-1 and 2-to-1 downstream evaluation